


What's my most valuable dj mix? An investigation using R and the Discogs API
'Easy questions' often require a lot of work for analysts to answer, to be honest


Welcome back to Data Rampage, and sorry for the delay in sharing new newsletter - work heated up a lot and then I was on vacation for several weeks in beautiful Savannah, Georgia. Now that I’ve been back for a week I’m ready to share the results of a little side project I started working on during my trip; and yes, I know this means a longer pause on my ongoing series on tracking design … I’ll be back to that soon!
So, what is this little project about? Basically, I was pondering the question, “I wonder which of my dj mixes has the most valuable records on average?”, and I decided to answer it in a data-driven way.
If you aren’t aware (although I mention it in literally every newsletter!), I’ve been a dj for 25+ years, and although I don’t really play in clubs any more (too much hassle with a family and full-time work), I still frequently record mixes and post them on my Soundcloud account. I’m also a weirdo who still mixes on vinyl instead of digital, mainly because (a) I love records, and (b) I spend enough time fiddling with digital displays as it is.
So, since I have a borderline unhealthy relationship with collecting records, I was pondering the value of my mixes, and I decided to see how easily I could answer the question. And it was … not that simple! But I did it, I got the answer I was looking for, and having done so, I thought it might be interesting for you, dear Data Rampage readers, to have me walk you through what I did, since it’s relatively rare for non-analysts to get a clear description of the end-to-end process of making a data analysis.
I’m going to write two newsletters on this; this first one will walk you through the logical flow of the project, and the second one will be about the actual code I wrote. If you want to see the code now, you can see it here on Github in these two files:
Framing the Problem
Let’s start with the problem: “what’s my most valuable dj mix?” is a vague question, it’s not concrete enough to be answered without further work.
That’s pretty typical when doing data analysis: refining the initial question to identify the business value and make it answerable. Let me give you a real example from my career: being asked by a designer “is this button on that page popular?” That’s not really an answerable question on its own (what does ‘popular’ mean?), so we had to dig in a bit to clarify that what they really wanted to know about was whether the landing page was working to launch visitors deeper into a funnel. In this case, knowing about the specific button was just the proxy for understanding the business impact of the page.
And so, in order to to understand the business impact we needed to map out and answer several other questions: how frequently do visitors click on the call-to-action button? How long do people spend on the screen? How far down do they scroll? What proportion of users ever even visit the screen? What’s the ratio of screen views to clicks?
In my case, ‘what’s my most valuable mix?’ meant clarifying these points:
What do I mean by most valuable?
How do I define ‘value’?
Where am I going to get this information from?
Let’s start with the first one; ‘most valuable’ can mean a few different things; it could be a total or an average. I decided that a total wouldn’t make sense for my case, because I don’t consistently use the same number of tracks in mixes - sometimes as few as 10, sometimes more than 50. Using a raw sum would just unfairly advantage the longer mixes.
So, I would need to calculate an average to effectively compare the ‘value’ of the different mixes. One way to think about value would be to literally use what I actually spent on each of the records, but, let’s get real, that’s insane. I have no idea what I paid for most of them! I could try to estimate them, but that’s stupid too. Where would I even start?
No, the only possible way to answer this question is to use information from Discogs, the pre-eminent online record database and marketplace.
How can I estimate the value of a record?

Let’s look at one example of a release listing page on Discogs: this is the page for ‘Lanterns’ by Tim Reaper, one of the key figures in the jungle revival of the last decade.
If we look at this page, we see a couple of interesting data points that could be used to assess the value of this record:
Current market prices
Historical prices
Both could work! To determine what is possible, I then went to the API documentation and had a look; which is where I found some very interesting things:
Historical prices are not available at all for a given release
For current market prices, the API returns only the lowest current price and the number of copies for sale
There is no way to use the API to get all of the current listings for a specific release; you need the listing ID to see prices
Unfortunate news! So I had to decide if I wanted to build a web scraper to collect the historical data and/or current listings … very quickly I decided that was crazy and would be too much work.
Brief sidenote: If you’re not familiar with web scrapers, that’s basically where you write a program to pull data directly from a web page and then format it into a usable format. It’s literally a last resort and I would never recommend writing one, as they are always painful to write and nightmares to maintain.
Fortunately, the API does provide a solution: a price suggestions method, where you can send a release ID and get back suggested prices for each of Discogs’ standard condition grades. This is what I would use; the next step is to figure out how to get a list of the relevant records and how to feed them into the price suggestions API.
Creating the Data Set
Now that I had a solution for getting the value of individual records, the next step was to define the data set, specifically how to get the records from each mix and then their value.
This turned out to be quite easy, because for many years I have been using Discogs’ Lists feature to list the individual records I’ve used in mixes; you can see all of my lists here. It’s been part of the process by which I release each new mix: I create a list featuring all of the records that I’ve featured, partly as a useful reference, and partly for SEO purposes.
For an example of a list, you can see this one for Berlin nach London, my most recent mix. Using the Discogs API, these are the steps I followed to create a data-frame with price recommendations for every record I’ve used:
Called the user lists resource to see all of my own lists
Filtered that data frame to only cover public lists and lists associated with mixes (I had some other lists) and created a vector of distinct list IDs
Called the list resource to get all of the items associated with each list ID and bundle them into a single data frame
Created a vector of distinct release IDs
Called the price suggestions resource for each release ID and bundle them into a single data frame (sometimes the API returns no results for a particular release ID, in which case I skipped adding it to the data frame)
Filtered to the suggestions for only VG+ quality releases (my most common quality level), then joined to the data frame created in step 3 to create the final data set
Diagrammed out, this is what the process flow looks like (with blue representing distinct API calls and yellow filtering processes):

One thing to note is that the Discogs API only allows you to make 60 calls per minute, so when you have large lists it can take some time. For step 5, for example, there were 3152 distinct IDs to churn through … that’s a lot when you can only grab 60 a minute! It took me almost an hour to get all of them, and I had to write the code in a way that it could fail and I could restart from where it failed instead of having to run it again from the top.
So no quick answers here …
Answering the Question
Finally (!), I had my data set, and I was ready to answer the big question that kicked off this whole process: what’s my most valuable dj mix?
Spoiler alert, it was this one, Drop The Hammer 12, a mix of old skool breakbeat hardcore, with a mean suggested price of 55 Euros (!):
To get this answer, I grouped my data frame by list name and calculated the mean and median suggested price for each mix, as well as the max and min values. And so it turned out that Drop The Hammer 12 was my most valuable mix. I did this one years ago and don’t really listen to it that often any more … so this was a little bit of a surprise! At the same time it’s quite understandable, as early 90’s rave anthems have become extremely collectable over the last decade, as guys like me enter into middle age, with widening midsections, more disposable income, and a sense of nostalgia.
Another interesting thing to do with the data set was to see the distribution of mean values across the whole set of mixes; you can see that Discogs thinks that VG+ copies of most of my records are in the 10-20 EUR bracket; or at least this suggests that I’m not making mixes with bargain basement tracks!

Another thing that is typically done when performing a data analysis, is to see if there’s anything else that’s interesting that you can glean from the data, so I decided to throw together a scatter plot to see if there was any relationship between the average value and the number of records I used in a given mix:

Um … no.
Can we add a Loess regression line to see the relationship between the factors?
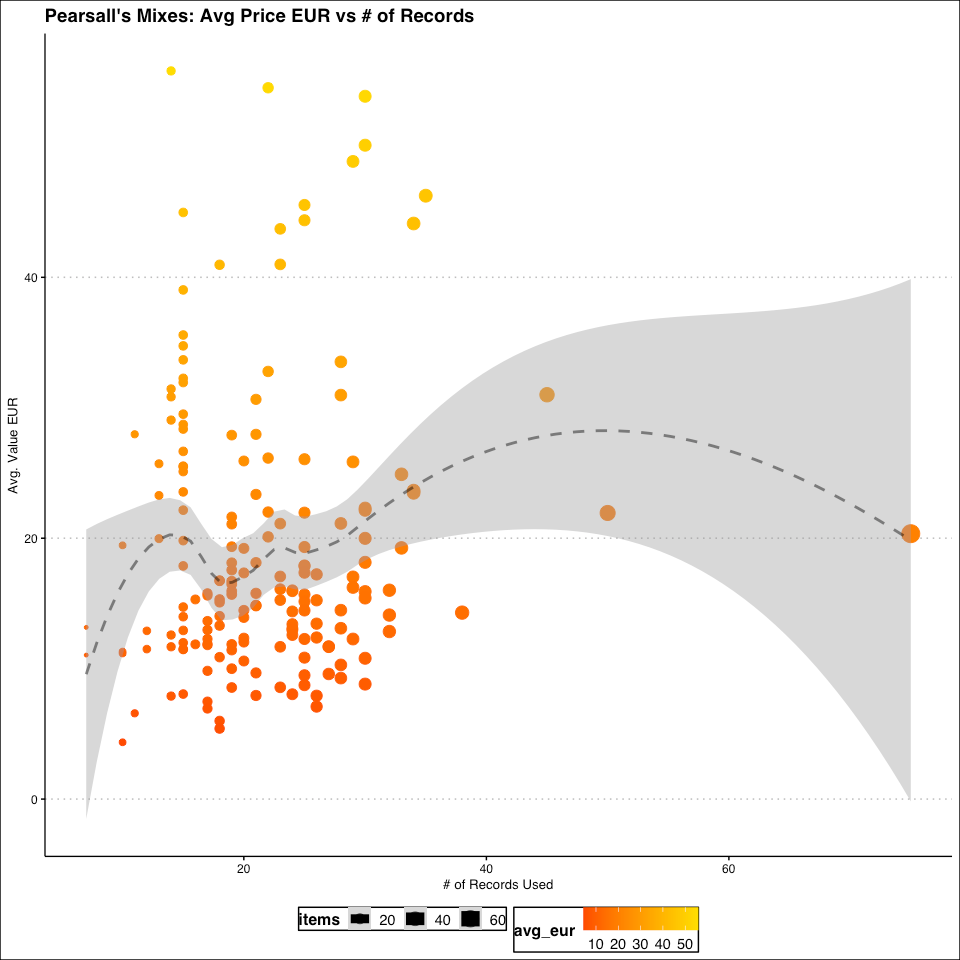
Hah! No, that didn’t work. (A common occupational hazard when doing data analysis)
Let’s try this again, to see the relationship between mean and median suggested prices, with bubble sizing based on the difference between maximum and minimum prices. This is an interesting one - are ‘expensive’ mixes so because I used many expensive records, or are they distorted by outliers? Let’s try the same chart as above, with the same regression method:

Well, that is quite interesting - the relationship between median and mean is quite close, as seen by the relatively straight regression line, as well as the narrow standard error shading. Based on this, I have an answer - the value of an individual mix is mostly a function of the overall value of the records used, as opposed to being something determined by pricy outliers.
So that’s it - thanks for reading. The next post will talk about writing an API connector in R (i.e. how I got the data needed for this post), and then I’m back to writing about tracking design.
If you missed out on that, you can read the last part in the series here:

One last (music) thing
For those who are curious, according to Discogs, the single most valuable record I own is this white label release of ‘Alicia’ by dubstep mastermind Mala; I bought it when it came out for something like 7 GBP and it’s now supposedly worth 286 EUR, which is pretty wild.
I used this track to conclude this mix, which was my second tribute to Mala (who is one of my all-time favorite producers):
Thanks for reading … more soon (I promise!)