
Thinking about Tracking Design, Part 1: What is tracking anyways?
Thinking about Tracking Design, Part 1: What is tracking anyways?
A new series about tracking design, starting with a fundamental question: what does it even mean?

Hello and welcome back to Data Rampage!
With this post, I'm kicking off a six (!) part series on tracking design.
What's tracking design, I hear you ask?
Tracking design is the art of designing an effective system for collecting behavioral data from your frontend services. Translated out of data jargon, that just means making decisions about what user actions you want to track on your website and/or mobile app.
It's a topic that I have found very interesting since I was first exposed to it many years ago. I also feel like it's a topic where it's hard to get useful information when you are getting started, or at least that was my personal experience. Lots of trial and error! That's not to say that there isn't good information out there - the challenge is more cutting through the noise and content spam to find what's useful, so with this series I want to make a small personal contribution to the wider data community by offering some hard-earned wisdom.
In this series I will be covering the following topics:
What is tracking anyways?
Why should you set up frontend tracking?
What should you track?
Approaches to tracking: Feature-based tracking
Approaches to tracking: Component-based tracking
Working with event data
To start with, I am going to be Captain Obvious and explain what is frontend tracking in the first place, since it’s clear to me that this is not necessarily well understood outside the data community. In the second part I will look at the overall question of why you might want to implement frontend tracking, which is really about achieving your business goals. In the third part I’m going to discuss what you need to consider when embarking on a tracking design project, such as the kinds of questions you need to ask, the compromises and trade-offs you are likely to face, plus some obvious pitfalls to avoid. In the fourth and fifth posts I will discuss two distinct approaches to tracking design: a component-based approach, which defines events based on UI components, and a feature-based approach, which defines events based on the product feature. In the final post I’m going to go one step past event collection to look at how you can take the resulting flood of raw event data and turn that into insights and answers.
Disclaimer time: Since the beginning of February I am an employee of Snowplow Analytics, one of the leading producers of behavioral data software, so I think that I should make it clear that all of the opinions I will express in this series are my own personal opinions, and not the official opinions of my employer.
What does it mean to track behavioral data?

I think it’s fair to say that behavioral tracking is not well understood outside the data world; the term ‘tracking’ itself sounds scary, like stalking! It makes people think about something very personal, a process where a website comes to know your deepest secrets, as with the Stasi agents in the German film Das Leben der Anderen (The Lives of Others).
The reality is more prosaic, however, so with this first post I would like to demystify this process and explain what is actually going on.
First, let’s clarify some of the terminology that will be used in this post:
The frontend: The software that you as a consumer actually interact with, i.e. the user interface of a website or a mobile app
The backend: The services in the background that power the frontend; you as the consumer don’t interact directly with the backend, but this is where information is stored (like account information), and there is a constant two-way flow of information between the backend and the frontend
Trackers: Small pieces of code (typically a JavaScript snippet on web and a Software Developer Kit or SDK on mobile apps) that are inserted into the frontend source code to capture relevant information and metadata about the way the customer interface is used
Cookies: Tiny files that are stored in the web browser; they can contain anything from authentication information (that you are in fact logged in to a site) to tracking information that is used to build a picture of the user. Cookies can either be first-party (set directly by the website) or third-party (set by another party, most commonly by a script from another company that is integrated into the website)
GDPR: A European Union directive governing data privacy, with a strong emphasis on gaining consent for tracking activities.
At the most fundamental level, event tracking means making a record of user activities on a website or mobile app. You as the user perform an action, and the tracker code in the frontend generates a little message detailing what happened (the record of the ‘event’) and sends it off to a server to be stored. This could be you viewing a web page, clicking on a navigation bar in a mobile app, playing a video, clicking on a text link … whatever.
There are so many analytics tools out there, but pretty much all of them have similar basic functionality. For the most part tracking tools, whether Google Analytics, Adobe Analytics, Snowplow, Segment, Mixpanel, Amplitude, etc, will have a certain set of events that are automatically captured, as well as the ability to capture additional events as custom events.
Automatically captured events typically include:
Page/screen views: A record of a web page or mobile screen being viewed (or at least loaded)
Time pings: Regularly spaced pings (for example, every 10 seconds) that can be used to reconstruct time on screen, and then rolled up to time on the service. Snowplow’s web tracker fires a ping if there was activity on a web page in the last x seconds (the amount is customizable), for example if the cursor was moved. This only fires when the tab is the active one in the browser to prevent false impressions of how long people are spending.
Link clicks: Clicks on a text link
Form events: Events related to filling in and submitting an HTML form
These are the events that are the most standardized across internet services, making it possible for trackers to automatically capture them without requiring developer support. These events on their own provide quite a bit of information about behavior, but of course there are other actions that users can do on websites and mobile apps, and so in order to track those actions developers need to add custom events.
A custom event is literally just a code snippet that tells the tracker that a certain event has happened. For example, let’s say that you want to have an event that fires every time a user switches a toggle on or off, and you want to attach a parameter called toggle_position to it. The developer would set the code snippet to fire after the toggle is switched, and would attach the extra information (generally referred to as ‘variables’ or ‘parameters’) to the event.
To give you a sense of how this might look in practice, here is how you would do it in Google Tag Manager:
dataLayer.push({'event':'toggle','toggle_position':'on'});And here is how it would look in Snowplow Analytics (you would first need to define a JSON schema for the event toggle):
snowplow('trackSelfDescribingEvent', {
event: {
schema: 'iglu:com.acme_company/toggle/jsonschema/1-0-0',
data: {
toggle_position: 'on'
}
}
});What kind of events would be tracked on a typical web page?
To give you a sense of what kind of events would be trackable on a typical web page, let’s look at the Soundcloud page for my most recent dj mix, which I’ve annotated to show the different types of events that you can track:
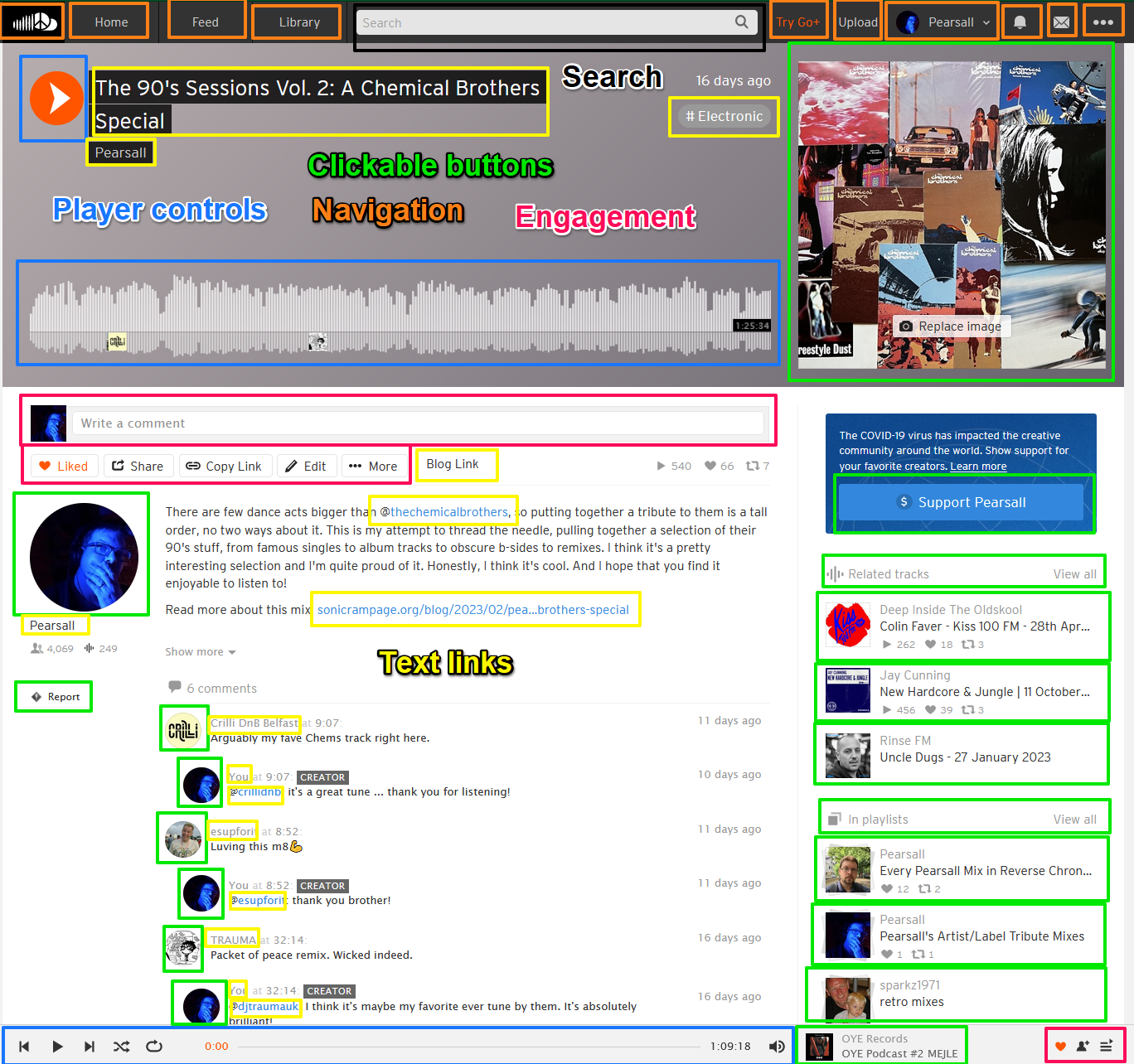
I know this is very busy, but there’s a lot happening on this page!
I’ve color-coded the rough event types, which are as follows:
Text links (yellow): These are clickable hyperlinks that will either take you to other pages within Soundcloud or to an external website.
Clickable buttons (green): These are buttons of various types that you can click to go to another page within Soundcloud (except for the cover image, which loads an overlay). Some go to profile pages, some go to other tracks, others go to playlists.
Navigation (orange): I’ve added all of the navigation elements in orange, although strictly speaking some are text links, and others produce drop-down menus.
Search (black): The search bar allows you to … search.
Player controls (blue): The player controls allow you to perform actions with the music file; this includes starting and pausing, dragging to a new position, changing tracks, adjusting the volume and shuffling or setting to repeat.
Engagement (pink): Engagement actions are ways for the user to engage with the track, including liking it, sharing it, reposting (for stuff that isn’t your own), adding comments, and so on
Now, many of the actions covered here will also be recorded to backend, since tracking them is essential to the fundamental functioning of Soundcloud. For example if you hit the play button or the like button, those have to be stored in the backend so that the correct counts of plays and likes can be displayed. While you certainly can do analysis on backend information, the advantage of capturing user behavior in the frontend is that you capture it alongside lots of contextual information that wouldn’t be captured in the backend.
Backend services are designed to support the user experience on the website, so by necessity they need to be as lean and as fast as possible; you only store the information that is absolutely necessary to the effective functioning of the service. Analytical databases, on the other hand, don’t (usually!) need to be accessed in real time, so they can store huge amounts of extra information.
What do I mean by this extra contextual information? Analytics services capture not just the raw event, but also a whole host of other dimensions, relating to traffic sources, device information, geography and more. Google will also join the information from Google accounts with other information they know about the user and make that available in the Google Analytics interface (although it’s not available in the raw event-level export to BigQuery). For example, here is the full list of automatically populated dimension fields in GA4:
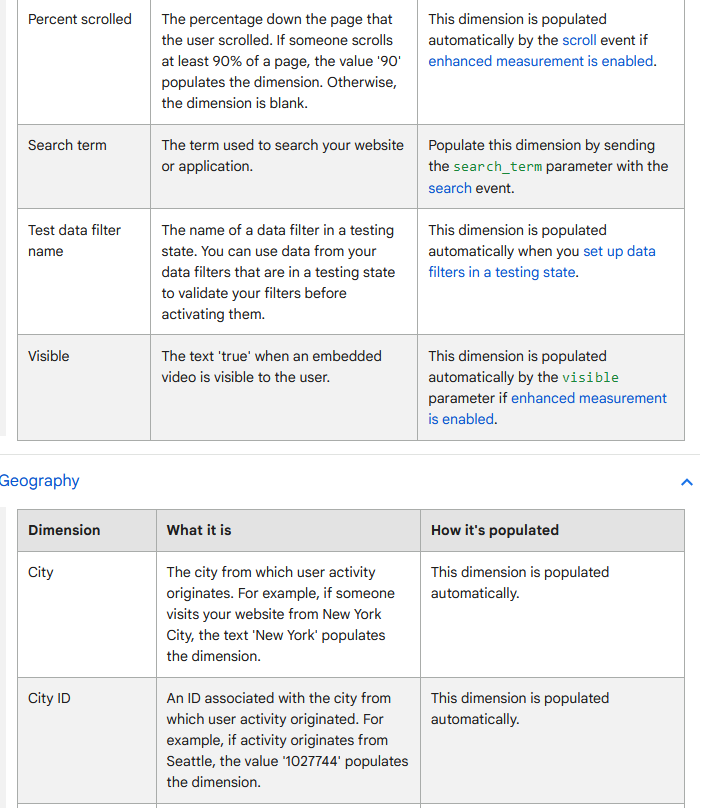
You can find similar levels of detail from all the providers; for example, here they are for Adobe Analytics, Amplitude, Segment, and, of course, Snowplow Analytics.
Now, why exactly data teams want all this contextual information is more a topic for the next post in the series, but just briefly the value of having this information is that it allows for a much richer variety of analyses than is possible purely with backend information. It can make it easier to pinpoint bugs as well as to understand the popularity (or not …) of certain features, and can be used to make decisions about what to work on next. It’s especially helpful for understanding user flows and for giving useful feedback about whether certain processes are well designed or not.
I can give you a simple example of the value of this contextual information: when I was working on the Commerzbank mobile app, we found that one of our payment options wasn’t getting the traction we had hoped. On further analysis, we found that usage of the feature was heavily affected by screen sizes … people with smaller screens simply didn’t see the option unless they scrolled down! So we did an a/b test where we tested moving it to the top of the screen from the bottom, and increased the uptake of the feature quite dramatically. This would not have been possible without the technical device information that was automatically captured by the tracker.
What information about you is captured?
Probably the most persistent question that non-specialists have about web and mobile tracking is what the service knows about them.
The answer is … it depends.
(Not an ideal answer, I know)
From the perspective of the typical website owner, new users are completely anonymous, and over time through different actions they might provide some more information about themselves (although not always!); I call this process the ‘user knowledge path’. This can start with registering with an email address and then continue through providing payment information (although most e-commerce sites use a service like Stripe instead of processing payments directly), and a real name and address.
This kind of information is known as Personally Identifiable Information (PII) and it is the most strictly regulated form of data, so in theory it should be subject to the most controls behind the scenes in terms of who can access it and who can see it. Well-run companies will have strict policies about which employees can see and interact with customer information; at one place I worked there were very strict controls on this and I never saw real customer identities or PII, only pseudonymous user IDs. Not all companies are so thorough, however …
To broadly generalize, the information that any one company has on you varies tremendously; tech giants like Google and Facebook have a vast amount of information on your behaviors, and that is what they use for automated ad targeting. A random e-commerce store might know your shopping behavior and your name and email address, but won’t know your demographic information, and a news site that you never sign in to will only know you by a browser ID. It varies a lot!
Personally, I have found that PII is of essentially no use for internal reporting or analysis, but marketers and sales people are often interested in it. For example, a typical question might be “which users performed these key actions and can we reach out to them to try to sell them our product?” This would then be used as a basis for a data analysis to build an email marketing list. This is why the GDPR places strict limitations on using personal data for advertising purposes, and why gaining consent is so crucial.
The reality is that any one individual’s information - like their event history - is just not very interesting or useful in isolation; it’s only valuable as a building block for aggregations, whether that is understanding product usage or for creating a mailing list.
One last (music) thing
As with all of my posts, I’m ending this one with one of my dj mixes, and I’m going to end this particular one with the mix I referenced above: my recent tribute to The Chemical Brothers, ‘The 90’s Sessions Vol. 2’:
My own personal history with the Chems goes way back to 1995, when their debut album Exit Planet Dust became one of the very first electronic albums I purchased at the tender age of 15. I’d been a precocious kid, into heavy metal and punk rock, and I’d loudly hated electronic music because it wasn’t ‘real’. I still don’t remember exactly how it happened, but something just clicked. I found myself listening to drum n’ bass on pirate radio, I started picking up dance magazines, I was listening to Kiss 100 FM in the evenings … it was like a switch had been flipped in my mind, and what had previously made no sense to me was suddenly uncovered in its full glory.
No vocals? Great, who cares about vocals.
Bass more important than treble? That’s fine, I’ll take any and all low frequencies.
Weird sounds? The more the better.
Repetitive beats? Repeat them until the end of time as far as I’m concerned.
That first album made a huge impact on me, and it still stands up today. It has straight-up dancefloor bangers and contemplative downtempo stuff; Saturday night and Sunday morning. What a listen!
I hope this was a useful read; feel free to ask me any follow-up questions in the comments or via email.
Next up is some discussion on why you might want to track via the frontend; and if you missed it, the last newsletter was about cleaning up messy data using R:

More soon!
Nice write up!