


Google Drive went nuts and duplicated tens of thousands of files; how did I use R and Python to tidy them up?
It's not like I was going to manually delete them all


This weekend I was doing some stuff on my computer when I got a weird notification: my external hard-drive was running out of space.
Huh?
As far as I knew, there was still something like 80 GB free, why was it running out?
A quick investigation led to the discovery that Google Drive’s sync function had run amok, and it had duplicated tens of thousands of music files. This external hard drive has my digital music collection, composed of stuff I ripped from my old cd collection (remember cd’s?), dj mixes that I downloaded and chopped up, and other bits and pieces that I had traded and collected over the years. There’s a lot of stuff there and I don’t want to lose it! Hence I pay for Google Drive so I can back up the collection for safe-keeping if (when) the hard drive dies.
Obviously, though, it’s not ideal when the software loses its mind and decides to randomly duplicate files instead of syncing them; to be honest, I’ve found the service much less reliable since Google replaced the old Windows app called ‘Backup and Sync’ with the specific Google Drive app. The old service worked perfectly, the new one doesn’t, and the only reason I can see that they sunset the old one is that it’s almost impossible for Big Tech to Just Leave Things Alone.
What’s the problem?

Anyways, enough complaining from me … see the image above for an example of what I found myself facing. In this image you can see that all the tracks from the Arcade Fire album ‘The Suburbs’ were inadvertently duplicated by Google Drive. You can see the duplicate mp3 files have had ‘(1)’ added to the end of the file name.
If this was just the odd album it would have been ok, I could have just bit the bullet and manually deleted them, but since the hard drive was out of space I knew that I was looking at tens and tens of gigabytes and something on the order tens of thousands of duplicate files.
Not ideal!
And frankly, I didn’t want to manually tidy them all up.
So I needed another solution; basically I needed to do this programmatically. And I thought it might be nice to share my solution with anyone else who might be interested; I know it’s not really the main topic of this newsletter, but why not, eh?
Fixing it with R
My first plan was to just fix it with R; I’m a huge fan of it as a programming language, it’s been something I’ve used for years to clean and manipulate data, to create visualizations, and to do data analysis. What many people don’t realize, however, is that R can also be useful for working with your own file system.
If you want to work with R, your best bet is to follow these steps:
Install RStudio as your IDE
Take some free R courses
Datacamp has a free Introduction to R course
When I started thinking about solving this duplication problem, I decided that the code that I wrote had to fulfill the following criteria:
It had to identify the duplicate files based on identifiable patterns in the file name
It had to be able to iteratively work through sub-directories top-to-bottom to ensure that it checked all relevant files
It had to then either move or delete the duplicate files iteratively, so that I would only need to run the command once
To that end I wrote the following three functions:
library(fs)
library(tidyverse)
library(purrr)
#make a function to generate a df of all files in a directory
dupe_finder <- function(directory,string) {
require(tidyverse)
#change the working directory to the specified directory
setwd(directory)
#recursively list all mp3 files
df <- tibble(files = list.files(pattern='.mp3$',recursive = T),
#create the full file path
file_path = paste(directory,files,sep='/'),
#check for duplicates using a string pattern
duplicate = str_detect(files,fixed(string)))
return(df)
}
#make a function to remove duplicates
dupe_remover <- function(df) {
require(tidyverse)
require(fs)
require(purrr)
#extract all duplicate file paths into a vector
files_to_remove <- df %>%
filter(duplicate == T) %>%
pull(file_path)
#iterate through them to delete them directly
purrr::map(files_to_remove,file.remove)
print('All files removed')
}
#make a function to move duplicates to a new destination folder
dupe_mover <- function(df,new_path) {
require(tidyverse)
require(fs)
require(purrr)
#extract all duplicate file paths into a vector
files_to_move <- df %>%
filter(duplicate == T) %>%
pull(file_path)
#iterate through them to move to the new path
purrr::map(files_to_move,file_move,new_path)
print(paste('All files moved to',new_path))
}I’ve added comments in the code, but these three functions work like this:
dupe_finder: This recursively works through the directory and all subdirectories, checking all mp3 files for the duplicate pattern, in order to generate a dataframe (a rectangular data structure, akin to a table but stored in-memory)dupe_remover: This takes the dataframe and deletes all duplicate filesdupe_mover: This is the same asdupe_remover, but instead of deleting, it simply moves the relevant files to a new folder
Let’s go back to that example that I showed before, with the Arcade Fire album that had many duplicates:
af <- dupe_finder('H:/My Music/rock/Arcade Fire - The Suburbs',' (1).mp3')The first line generates a data-frame which looks like this:
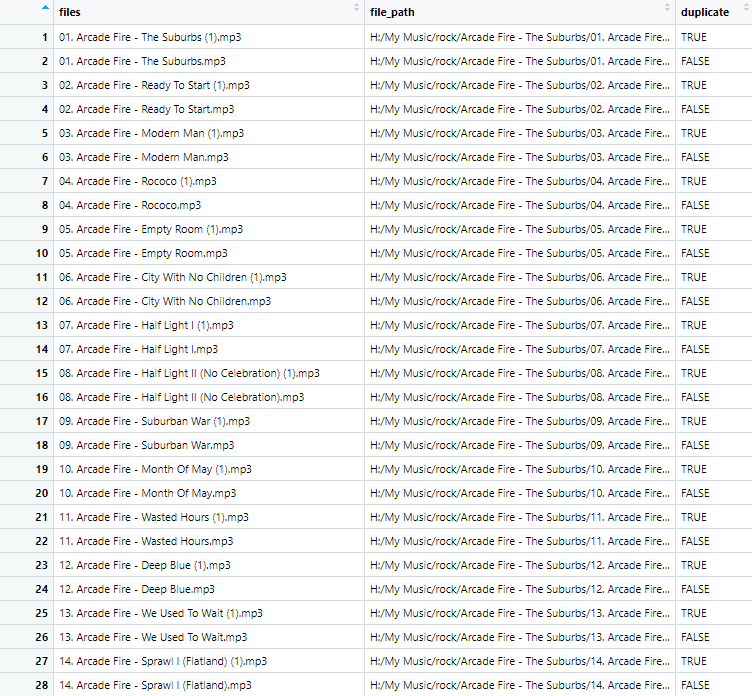
As you can see, it’s correctly identified the duplicate files, based on the pattern I provided as an argument.
Now let’s move the files to a new location:
dupe_mover(af,'H:/My Music/dupe_test')Now you can see that I’ve quickly (and efficiently!) moved all the duplicate files to a new folder I created called ‘dupe_test’:

Nice, huh? But that’s just doing one folder, this code can quickly run through a full tree of folders and sub-folders; as we can see when we run the code on the entire rock directory:

If the image is too small, you can see that there were 2245 mp3 files to start with in the rock directory. This is what happens when we move out the duplicate files:

There’s now only 1499 mp3 files - I’ve now moved out 796 duplicate files, which took up 5 GB of space!
This is the example code for working with the functions:
#test this by moving some files
rock <- dupe_finder('H:/My Music/rock',' (1).mp3')
dupe_mover(rock,'H:/My Music/dupe_test')Problem solved! Now I have a method for cleaning up my external hard drive, and hopefully once I reinstall Google Drive it will behave in a less cursed way.
Fixing it with Python
Since R is a relatively niche language, generally only used by data people, I thought I would also translate the code into Python, a much more popular programming language.
Honestly, I prefer working in R, but Python is fine as well, so here’s the code in Python.
There are lots of ways to install Python, but an easy way is to install Anaconda
There are lots of IDEs for working with Python; I usually work in Jupyter Notebook
There are tons of free Python courses online
I was feeling lazy, so I asked ChatGPT to translate my R code into Python, and it spit out an answer really quickly, which was awesome … but the code didn’t work, so I still had to translate it myself!
Without further ado, here are the same three functions, rewritten in Python. I’m definitely not as proficient in Python as in R, so they aren’t as elegant, but they do work (or at least they work on my Windows machine):
import os
import pandas as pd
import shutil
import glob
def dupe_finder(directory, stringval):
import glob
os.chdir(directory)
file_df = pd.DataFrame()
#check if there are sub-directories
x = set([os.path.dirname(p) for p in glob.glob(directory+'/*/*')])
#one operation for sub-directories
if len(x) > 0:
folders = os.listdir(directory)
if 'Thumbs.db' in folders: folders.remove('Thumbs.db')
for i in range(len(folders)):
new_path = directory + '/' + folders[i]
os.chdir(new_path)
temp_files = os.listdir(new_path)
temp_df = pd.DataFrame({'files': temp_files,'duplicate': [stringval in f for f in temp_files]})
temp_df['file_path'] = new_path + '/' + temp_df['files']
temp_df = temp_df[temp_df['files'].str.endswith('.mp3')]
file_df = pd.concat([file_df,temp_df])
#another operation for direct folders
else:
temp_files = os.listdir(directory)
temp_df = pd.DataFrame({'files': temp_files,'duplicate': [stringval in f for f in temp_files]})
temp_df['file_path'] = directory + '/' + temp_df['files']
temp_df = temp_df[temp_df['files'].str.endswith('.mp3')]
file_df = pd.concat([file_df,temp_df])
return file_df
def dupe_remover(df):
files_to_remove = df[df['duplicate'] == True]['file_path'].tolist()
for file in files_to_remove:
os.remove(file)
print('All files removed')
def dupe_mover(df, new_path):
files_to_move = df[df['duplicate'] == True]['file_path'].tolist()
for file in files_to_move:
shutil.move(file, new_path)
print('All files moved to ' + new_path)If you have any issues with the code or whatever, feel free to leave a comment or send me an email.
Hopefully this helps you!
One last (music) thing
As I mentioned before, I’ve been a dj for 25 years, so I’ve decided to end each newsletter with one of my mixes from my (extremely extensive!) back catalogue.
With this edition I’ve decided to share something new that I’ve just put up on Soundcloud; it’s a tribute to a famous London nightclub that I never went to … if that makes sense! Speed was a super-influential night that pioneered a deeper, more melodic style of drum n’ bass in the mid-90’s, so I’ve made this mix of some tunes from that era. It’s both frantic and relaxing … I like it!
In case you missed it, this was the last newsletter:

Thanks again for reading!